
연구/강화학습
RLlib 기초 - 예제 (grid world)
남하욱
2024. 1. 14. 20:45
저번 글에 이어서, RLlib을 이용한 간단한 예제를 설명하면서 RLlib을 사용하는 방법을 설명하려고 한다.
이 예제의 환경은 다음과 같다.

- 목표 : 3*3 grid의 왼쪽 위(state 0)에서 출발하여 오른쪽 아래(state 8)에 최단 경로로 도착
- state : 3*3 grid에서 현재 위치
- action : 현재 state에서 상하좌우 중 한 칸 이동하는 동작 { 0, 1, 2, 3 }
- 0 : 위
- 1 : 아래
- 2 : 오른쪽
- 3 : 왼쪽
- reward : 각 action 실행마다 음수 값 (양수가 아닌 이유 : reward가 양수면 목표에 도달하지 않고 loop를 돌며 무한정 reward를 얻음)
- 해당 칸으로 이동이 불가능 할 때 : -10 ( 큰 패널티, 벽에 부딪히는 행위는 많이 잘못된 행동이라 학습시킴)
- 이동이 가능 할 때 : -1
- 목표(state 8)에 도달 했을 때 : +100
환경 Class
class MyEnv(gym.Env):
def __init__(self, env_config = None):
# 액션은 4개, 상태는 9개(3*3 칸)
self.num_action = 4
self.num_state = 9
# Discrete(N)은 {0,1,2,...,N-1} 중 하나가 되게하는 space
self.action_space = spaces.Discrete(self.num_action)
self.observation_space = spaces.Discrete(self.num_state)
self.state = 0
self.path = [0]
def reset(self, seed=None, options=None):
self.state = 0
self.path = [0]
return self.state, {}
def step(self, action):
terminated = False
if action == 0 : # up
if self.state < 3:
reward = -10 # 없는 길을 가려고 하면 -10
else:
self.state -= 3
reward = -1 # 한 칸 움직일 때마다 -1
if action == 1 : # down
if self.state >5:
reward = -10 # 없는 길을 가려고 하면 -10
else:
self.state += 3
reward = -1 # 한 칸 움직일 때마다 -1
if action == 2 : # right
if self.state % 3 == 2:
reward = -10 # 없는 길을 가려고 하면 -10
else:
self.state += 1
reward = -1 # 한 칸 움직일 때마다 -1
if action == 3 : # left
if self.state %3 ==0:
reward = -10 # 없는 길을 가려고 하면 -10
else:
self.state -= 1
reward = -1 # 한 칸 움직일 때마다 -1
if self.state == 8: # 도착지점인 8번 state
terminated = True
reward += 100
else:
terminated = False
return (self.state, reward, terminated, False, {})
학습 Code
ray.init()
# 4000번의 시행(아마 iteration 기본값)을 총 10번 시행하며 학습
for i in range(10):
result = agent.train()
print(pretty_print(result))
# 마지막이면 학습된 agent 저장
if i == 9:
checkpoint_dir = agent.save().checkpoint.path
print(f"Checkpoint saved in directory {checkpoint_dir}")학습된 agent 불러와서 실행 Code
ray.init()
# 학습된 agent가 저장된 경로 지정, 불러오기
checkpoint_path= "/tmp/tmp_y3ntm7z"
agent = Algorithm.from_checkpoint(checkpoint_path)
# 실행해보기 전, 초기값 설정
env = MyEnv()
obs,info = env.reset()
terminated = False
print(obs)
# 한 episode가 끝날 때 까지 학습된 agent로 동작
while(terminated == False):
action = agent.compute_single_action(obs)
obs, reward, terminated, truncated, info = env.step(action)
# 이동한 경로 출력
print(obs)전체 Code
import gymnasium as gym
from gymnasium import spaces
import ray
from ray.rllib.algorithms import ppo
from ray.tune.logger import pretty_print
from ray.rllib.algorithms.algorithm import Algorithm
class MyEnv(gym.Env):
def __init__(self, env_config = None):
# 액션은 4개, 상태는 9개(3*3 칸)
self.num_action = 4
self.num_state = 9
self.action_space = spaces.Discrete(self.num_action)
self.observation_space = spaces.Discrete(self.num_state)
self.state = 0
def reset(self, seed=None, options=None):
self.state = 0
return self.state, {}
def step(self, action):
terminated = False
if action == 0 : # up
if self.state < 3:
reward = -10 # 없는 길을 가려고 하면 -10
else:
self.state -= 3
reward = -1 # 한 칸 움직일 때마다 -1
if action == 1 : # down
if self.state >5:
reward = -10 # 없는 길을 가려고 하면 -10
else:
self.state += 3
reward = -1 # 한 칸 움직일 때마다 -1
if action == 2 : # right
if self.state % 3 == 2:
reward = -10 # 없는 길을 가려고 하면 -10
else:
self.state += 1
reward = -1 # 한 칸 움직일 때마다 -1
if action == 3 : # left
if self.state %3 ==0:
reward = -10 # 없는 길을 가려고 하면 -10
else:
self.state -= 1
reward = -1 # 한 칸 움직일 때마다 -1
if self.state == 8: # 도착지점인 8번 state
terminated = True
reward += 100
else:
terminated = False
return (self.state, reward, terminated, False, {})
ray.init()
# 밑의 코드를 학습 하기 전과 후 구분하여, 현재 할 것만 남기고 다른 건 주석처리하기
######################## 학습 하기 전 #########################
agent = ppo.PPO(env=MyEnv)
for i in range(10):
result = agent.train()
print(pretty_print(result))
if i == 9:
checkpoint_dir = agent.save().checkpoint.path
print(f"Checkpoint saved in directory {checkpoint_dir}")
############################################################
######################## 학습 된 후 ##########################
checkpoint_path= "/tmp/tmp_y3ntm7z"
agent = Algorithm.from_checkpoint(checkpoint_path)
env = MyEnv()
obs,info = env.reset()
terminated = False
print(obs)
while(terminated == False):
action = agent.compute_single_action(obs)
obs, reward, terminated, truncated, info = env.step(action)
# 이동한 경로 출력
print(obs)
#############################################################실행 결과
처음에는 다음과 같이 학습이 되지 않아 벽에도 부딪히고, 목적지에 가는 동안 돌아가는 모습을 보여줌.
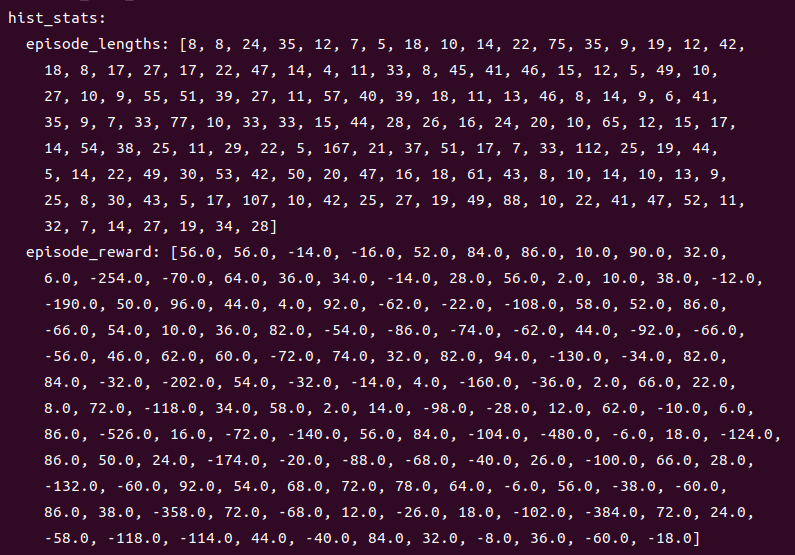
학습이 조금 진행된 후에는 다음과 같이 대부분 4회(최소 시행)만에 목적지에 도달하였고, 벽에 부딪히는 일도 거의 없어짐.


학습이 종료된 후 다음과 같이 agent가 저장된 경로가 출력된다.

이 경로를 이용하여 한 episode를 실행하면 다음과 같은 경로로 이동하였다고 출력하는 모습을 볼 수 있다.

